[ISSUE #9] The Bitter Lesson, RoboCat, Immersive View, MediaPipe Plugins
What's up with vision ML?

This week I’m taking a much-needed break from LLMs. After writing today’s newsletter, I realized it’s unintentionally Google-centric. Hope you enjoy this week’s tech tidbit :)
In this issue -
🏡 The tech behind Google Map’s Immersive View
✍🏽 The Bitter Lesson by Richard Sutton
😺 DeepMind’s RoboCat
🖼️ Controllable Image Generation Process
Reconstructing Indoor Spaces 🏡
In February 2023, Google Maps launched Immersive View, allowing users to tour a city digitally and simulate the upcoming weather on top of the rich, digital model. You can glide into the street view and explore a restaurant from the inside to help you decide whether you want to make that date reservation. This is made possible by an advanced AI technique called neural radiance fields (NeRF).
The way NeRF works is by collating a bunch of photos of a place into a coordinate-based neural network called a neural field. NeRF has essentially solved the challenge of scene reconstruction, but when offering the feature as a product, certain concerns need to be tackled -
Reconstruction quality and experience should be consistent across all venues.
Since Google’s street views, user-submitted photos, and panoramas are being used to reconstruct the scene, potentially personally identifiable information should be removed.
The digital experience should be device agnostic.

The pipeline consists of the following steps -
Photo capture and preprocessing:
Multiple dense, rich photos of the object from various angles to better discover its shape and how it interacts with light.
Environmental settings shouldn’t change (e.g., lighting), and camera movements during capture should be minimized.
Any sensitive information captured is scanned and blurred for privacy.
NeRF reconstruction:
Unlike the traditional ML models, a new NeRF model is trained on every newly captured location.
Scalable user experience:
Once the NeRF is trained, the digital creation can be viewed from any angle and can be traversed freely.
Every new viewpoint warrants a new render of the digital world, which is compute-intensive, and hence Maps offers us a fully rendered 360° video player for the user to look around freely.
The Bitter Lesson ✍🏽
Richard Sutton, author of the famous book “Reinforcement Learning: An Introduction” has written a blog post on how modern research in the deep learning field sometimes focuses on the less effective success route. It’s a very interesting read, and I have summarized the main points here.

He starts off by mentioning Moore's law and that the general methods that leverage computation are ultimately the most effective. On the other hand, researchers seek to leverage their human knowledge of the domain to seek an improvement that makes a difference in the short term. But in most cases, the human-knowledge approach tends to complicate methods. Following are some exhibits of the bitter lesson throughout history -
Chess: The method that defeated world champion Kasparov in 1997 was based on a massive deep search. This search-based approach using specialized hardware and nominal software was frowned upon but was the most effective. On the other hand, human-knowledge-based chess approaches couldn’t achieve the same kind of success, and hence the researchers were distraught and disappointed.
GO: A similar story followed suit when initial efforts were taken to avoid searching and use the game's special features. But all those efforts were in vain once the search was applied effectively at scale. This paradigm of search was further bolstered by employing self-play. By allowing self-play and learning in general, it reduced the computational burden.
Search and learning are the two most important classes of techniques for utilizing massive amounts of computation in AI research.
Speech recognition: Knowledge of words, phenomes, human vocal tract, etc., proved to be not as useful as applying statistical models at scale. More computation using statistical models such as Hidden Markov Model (HMM) out-scored the knowledge-based methods. This gave rise to deep learning in the natural language field and resulted in the conception of large language models where statistics and computation dominated the field.
Computer vision: There was a time when vision models used hand-crafted features such as canny edges, contours, SIFT features, etc., to train a conventional ML classifier. Modern deep learning lets the machine figure out these patterns independently, credit to more data and computation cycles. These deep learning models not only eliminate the need for hand-crafted features but also succeed in finding obscure features which otherwise couldn’t be thought of lest made use of in improving accuracy.
Finally, the bitter lessons -
Building in how we think does not work in the long run
Search and learning are the two methods that are able to scale with increased computation
We should strive to build only meta-methods to find and capture the arbitrary complex.
We want AI agents that can discover like we can, not which contain what we have discovered. Building in our discoveries only makes it harder to see how the discovery process can be done.
RoboCat 😺
The resistance to building general-purpose robots comes from the time it takes to collect real-world data for its training. This problem aligns really well with the “Bitter Lesson” mentioned above that knowledge-specific training will only get you so far. On the back of this lesson (or maybe unbeknownst), DeepMind has introduced a self-learning robot.
RoboCat is the first agent to solve and adapt to multiple tasks and do so across different, real robots.
The RoboCat can pick up a brand new task with as few as 100 demonstrations which is very impressive! It is able to achieve this feat by drawing from its diverse training dataset as well as generating synthetic data points for itself from the given demonstrations. This is an important step toward a general-purpose robot.
How RoboCat improves itself
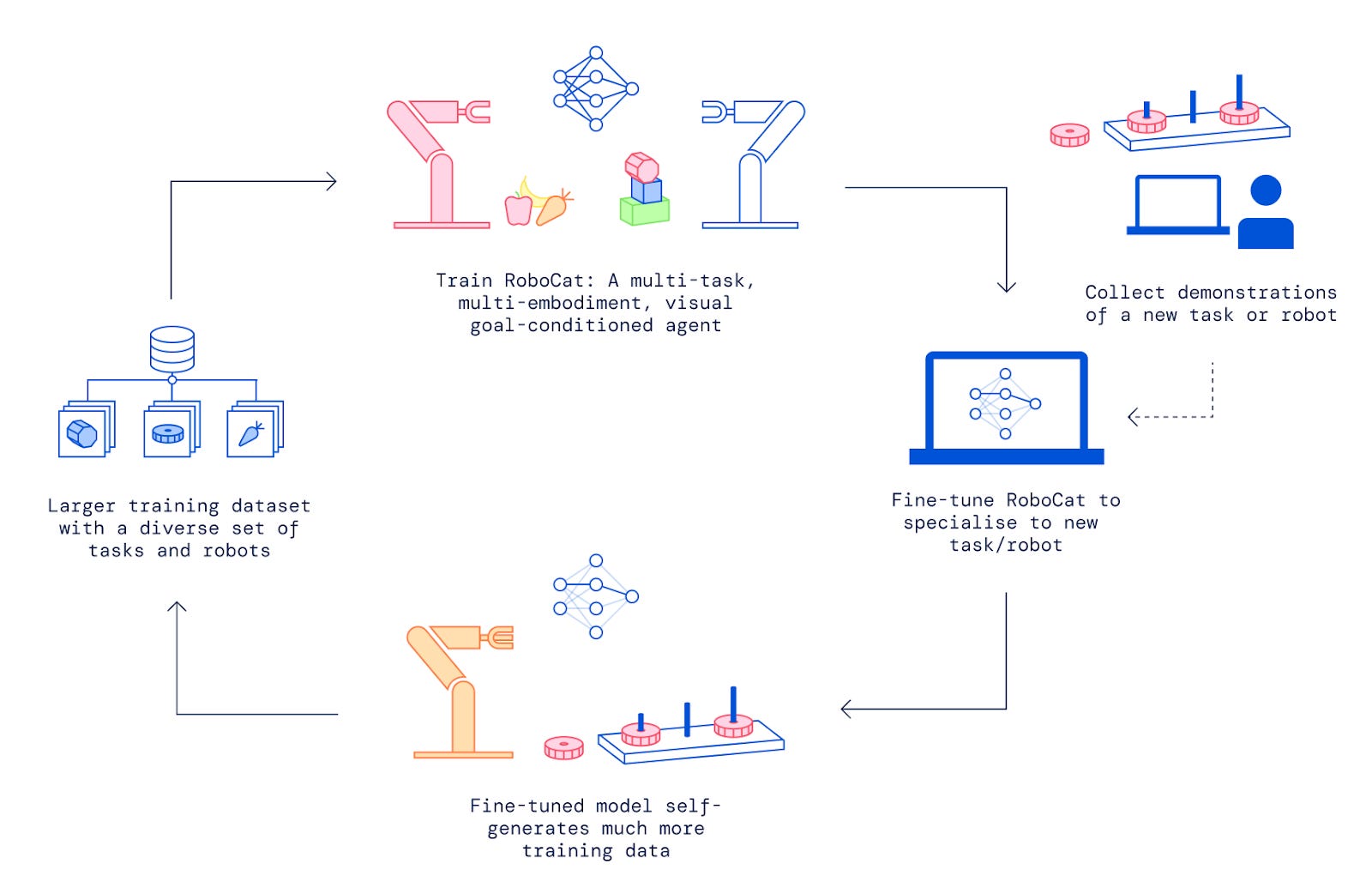
Collect a couple of hundred demonstrations from a real-world arm (controlled by a human)
Fine-tune the RoboCat on this small training sample to create an intermediary model whose sole purpose is to generate synthetic training data.
Combine the real demonstrations and synthetic demonstrations, which are then incorporated into RoboCat’s training dataset.
Train a new version of RoboCat on this new training dataset.
Furthermore, because of diverse training data, RoboCat is able to adapt to different types of robot arms (two prongs vs three prongs).
It’s quite serendipitous that I learned about RoboCat because the learning principle it follows is in line with the “Bitter Lesson.” This line in the article sums up the principle -
RoboCat has a virtuous cycle of training: the more new tasks it learns, the better it gets at learning additional new tasks.
Controllable Image Generation Process 🖼️
The diffusion models for text-to-image generation are trained to create images from noise. This means you lose control of the generated output bound by your textual accuracy after providing the model with a text prompt. What if you have a concrete idea of the general shape of the face and the direction it is looking OR how far a car should be from the camera, OR where the hands of the subjects should be situated in the generated output?
Researchers from Google have developed plugins for these existing generative models, which help set the stage for a text prompt instead of generating the image from scratch. This level of granularity gives us control of the image generation to a certain extent. They have developed four different plugins -
Face Landmark

Holistic landmark

Depth

Canny Edge

Furthermore, these are
Plugable: It can be easily connected with existing pre-trained models
From scratch: Can be trained from scratch instead of using pre-trained weights from the base model
Portable: Because of the integration with MediaPipe, these models can be run on edge devices (mobile devices)
Interesting things around the world 🌏
I scroll through endless articles and Reddit and Twitter posts (so you don’t have to) and deliver the cream of the crop to you! If you would like a copy of this issue in your mailbox the next time I write, consider subscribing 🤗 Thanks for reading!