[ISSUE #5] LoRA, QLoRA, fMRI to Image, Disagreement Model, Automated Code Reviews
Ever wondered how you can fine-tune the large language models yourself?

I read some interesting articles and papers this week which I couldn’t help but share. I feel the ideas that have been shared can be used to make large language models more accessible and usable.
In this issue -
Smart annotation of unlabelled text data.🤝
Google’s solution to automating code reviews.👨🏽💻
Microsoft’s novel technique to fine-tune large language models (LLM)⏩
Quantization technique to take fine-tuning a step further🏃🏻
Turning brain activity into images 🤯
And I end it with some cool stuff that I found while mindlessly scrolling Twitter. So get a cup of tea/coffee and enjoy this week’s read :)
Articles📄
Large Disagreement Models 🤝
How about using LLMs as an assistant to annotate unlabelled data?
Obviously, with a bit of prompt engineering, you might be able to perform your downstream task with a decent accuracy but it has a few disadvantages. Number one is the cost to run inference of a bloated generic LLM and second is the practical constraint on using a text-to-text model.
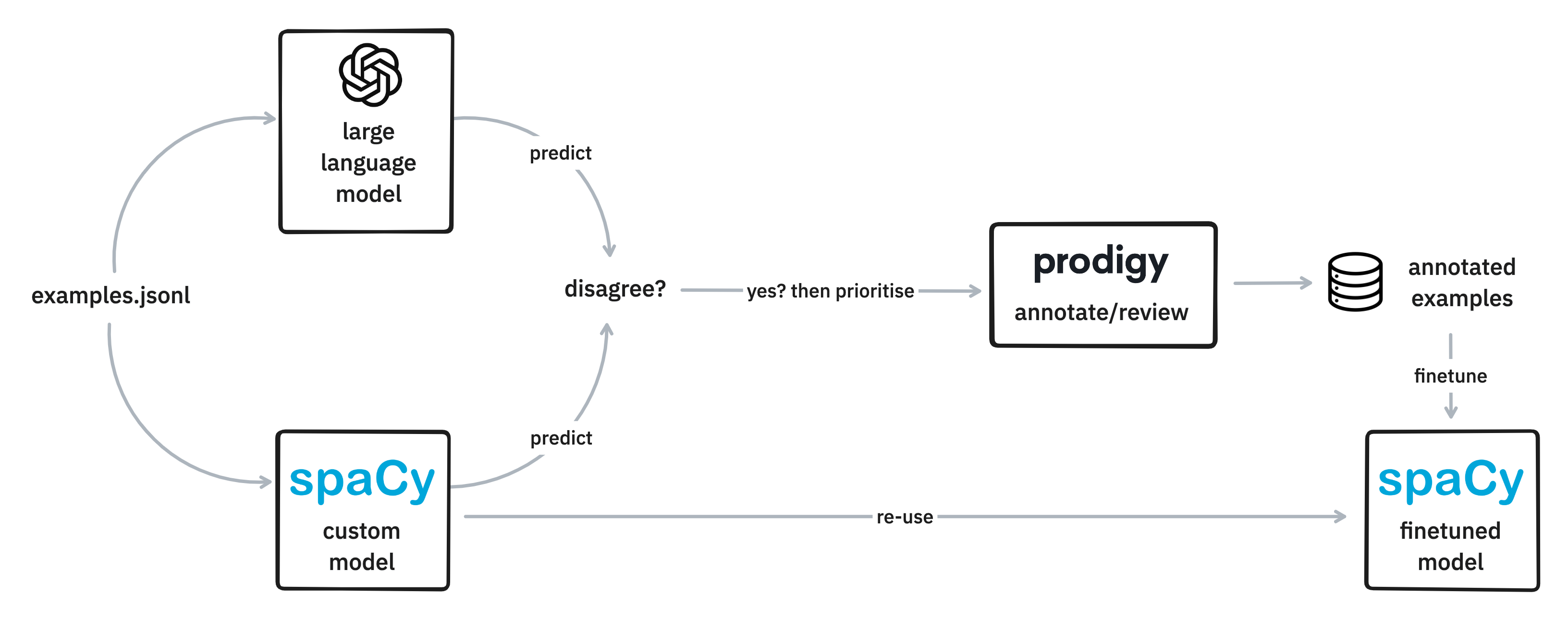
This article explores a new method to prioritize the annotation of unlabelled data using LLMs. The author speaks about letting the LLM and your custom-trained model - both predict the outcome. If they disagree, prioritize that particular instance of annotation. Update the annotation using a tool like Prodigy and fine-tune the existing model with the most interesting/difficult labels.
They have also provided a demo on leveraging data from the Guardian’s (news) to train a Named Entity Recognition (NER) model to extract organizations and person entities. And it’s safe to say that it dramatically increases ROI on time spent annotating.
Resolving Code Review Comments👨🏽💻
The engineers at Google have identified the following problems -
A significant amount of authors’ and reviewers’ time is invested in the process of code review
The required active work time that the code author must do to address reviewer comments grows almost linearly with the number of comments.
They proposed an ML solution to automate and streamline the code review process by proposing code changes based on a comment’s text. This ML-powered code-change process has been rolled out to the Google engineers already and the feedback indicates an increase in productivity.

This was powered by a large sequence models for software development activities called Dynamic Integrated Developer ACTivity (DIDACT). Unlike Github’s Copilot, it is trained on the process of software development instead of the end result of a coding journey. The model is aware of the context of the development including the action taken in response to certain inputs (code reviews).
Papers📝
LoRA: Low-Rank Adaptation of Large Language Models ⏩
What?
LoRA is a novel technique introduced by Microsoft researchers to deal with the problem of fine-tuning large-language models.
Why?
As language models have progressively become more generic and thus large (more parameters), it has become growingly difficult to adapt to specific downstream tasks or domains. This is because fine-tuning all the model parameters (175B parameters for GPT-3) is time-consuming, and computationally and memory expensive.
How?
Unlike the normal Stochastic Gradient Descent (SGD) process of forward pass → backpropagate → update parameters, the pre-trained weights are kept frozen and only the delta weights are manipulated.
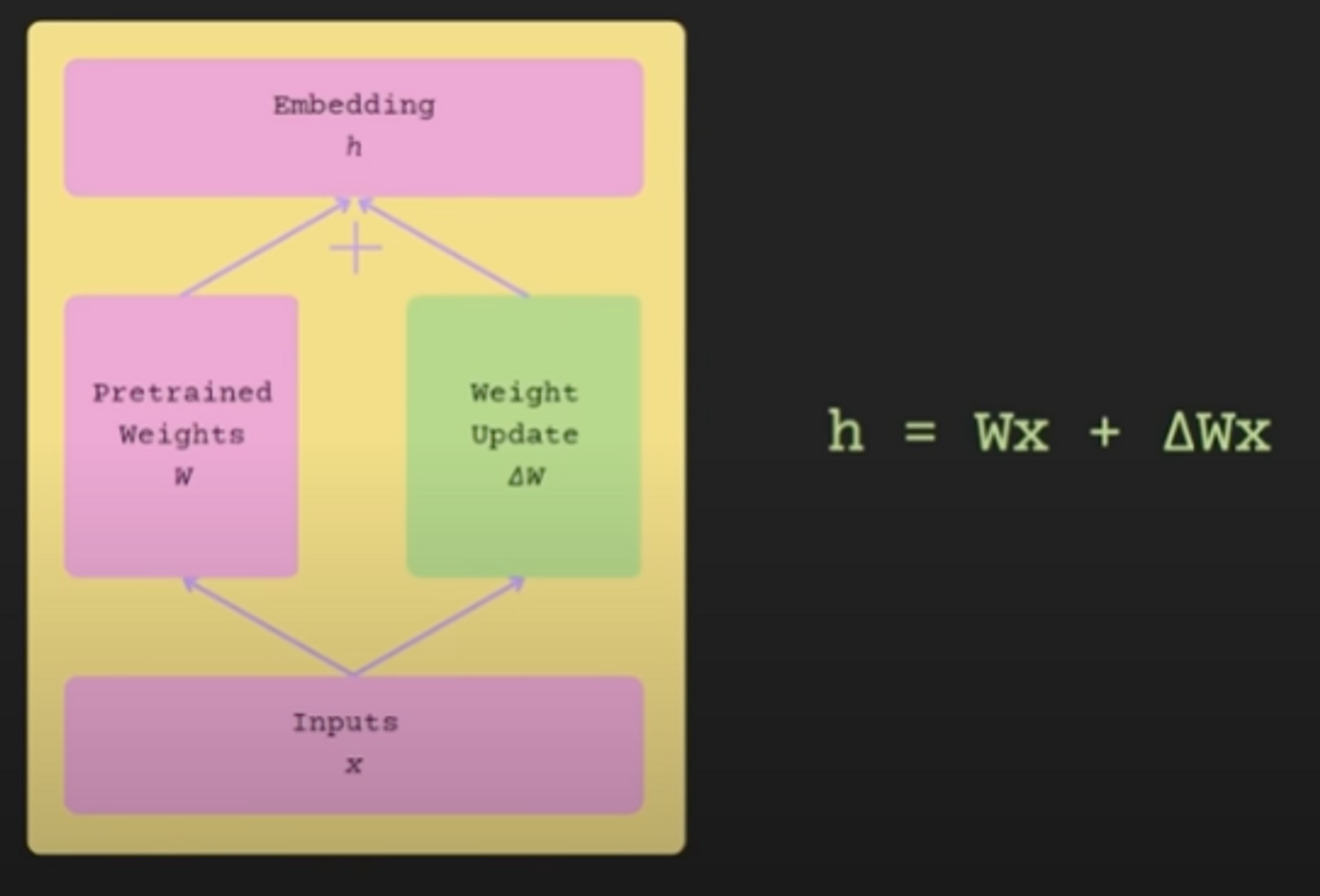
The crux of the idea is to train the delta weights using the custom data gathered for the downstream task. The delta weights are further broken down into low-dimensional representations of the original parameter matrix.
As explained in this tweet, let’s say the original weight matrix W is 100*100 (10k parameters), instead of training those many parameters we can represent it as a multiplication of two matrices WA and WB with dimensions 100x5 and 5x100.

So essentially we would need to fine-tune 1000 parameters instead of the original 10k parameters - a whopping tenfold reduction!
The best part is that it incurs zero additional inference latency. Also, the authors of the paper have discovered rank 8 to be the most optimal rank.
Making LLMs accessible with QLoRA 🏃🏻
Wouldn’t it be a money-saver to fine-tune large language models instead of paying the OpenAI over-lords in data and dollars? QLoRA allows us to train Facebook’s 65 billion parameter LLaMA model (and many others) using a 48 GB of GPU memory which otherwise warrants a whopping 780 GB of GPU memory.
How did they achieve this?
Reduces memory usage while preserving full 16-bit finetuning task performance
QLoRA backpropagates gradients through a frozen 4-bit quantized pretrained language model into LoR Adapters (LoRA)
List of innovations to save memory
4-bit NormalFloat (NF4)
double quantization (quantizing the quantization constants)
paged optimizers (manage memory spikes)

Some observations by the authors
The Guanaco family of models outperforms previously openly released models on the Vicuna benchmark (99.3% of the performance level of ChatGPT)
GPT-4 and human evaluators ranked 1000 models in the Guanaco model family and the authors found that for the most part (largely) they both agree on the leaderboard performance of the models.
Data quality is far more important than dataset size.
A comparison with LoRA
Most of the memory footprint comes from activation gradients and not from learned LoRA parameters.
For example, for a 7B LLaMA model trained on FLAN v2 with a batch size of 1, with LoRA weights equivalent to the commonly used 0.2% of the original model weights, the LoRA input gradients have a memory footprint of 567 MB while the LoRA parameters take up only 26 MB.
Reconstructing the Mind's Eye 🤯
How cool/creepy would it be if we could project our thoughts on a screen in real-time? That seems like a serious violation of privacy but also a peek into the dystopian future.
The authors of the paper have taken functional MRIs (fMRI) also known as brain activity and turned them into images. There are two main approaches -
Retrieve the most similar image from a given list of images.
Generate the image from the given brain activity using generative models.
Image Retrieval

The authors boast about the CLIP fMRI embeddings that are produced through MindEye network.
Using these embeddings, they are able to retrieve similar images from the LAION image dataset with an accuracy of 93.2%.
They achieve this by taking a cosine similarity between the embeddings produced from MindEye and CLIP hidden layer embedding of the LAION images.
Image Reconstruction

The output from MindEye, which is basically aligned with the CLIP embedding latent space, can be used with any pretrained image generation model that accepts latents from CLIP image space.
After trying several image generation models, the authors decided to go with Versatile Diffusion.
For each test brain sample, they produce not one but 16 CLIP fMRI embeddings to increase the probability of an accurate depiction.
Each of these 16 embeddings is then fed through an image generation module (Versatile Diffusion, in this case) to get 16 reconstructed images.
The quality of these images is then improved by using a denoising process (img2img) and the best of the 16 images is chosen.
Interesting things around the world! 🌏
Photoshop Generative Fill - Photoshop released its beta generative fill feature and people are getting creative with it.
Falcon LLM on Macbook with CoreML - This person has built a Swift app that runs the Falcon family of models (7B parameters) on a Macbook using CoreML.
Multimodal language model - You can now chat using text AND images.
I scroll through endless articles, and Reddit and Twitter posts (so you don’t have to) and deliver the cream of the crop to you! If you would like a copy of this issue in your mailbox the next time I write, consider subscribing 🤗 Thanks for taking the time to read!