[ISSUE #14] LinkedIn's LLM-powered text-to-SQL solution using agents 🤖
Text-to-SQL is now commoditized.

This issue is about how LinkedIn created a text-to-SQL bot, which is now used company-wide. According to their survey, 95% of the users have rated the bot’s accuracy as “passes” and 40% rated it as “very good” or “excellent” which instills some confidence in deploying such a bot in your organization!
This article outlines -
the motivation for text-to-SQL bot
the challenges LinkedIn faced
the solutions they came up with to combat the above challenges
the agentic workflow they used to generate queries
how they focussed on UI/UX for better adoption of the tool
the benchmark they created for the evaluation of the tool
I scroll through endless articles and Reddit and X posts (so you don’t have to) and deliver the cream of the crop to you! If you would like a copy of this issue in your mailbox the next time I write, consider subscribing. It’s free! 🤗 Thanks for reading!
The need for text-to-SQL
In my previous job in the legal vertical, one of my duties as a data scientist was to provide and analyze data for our management and stakeholders. This involved writing complex queries on top of our database.
While it is equally essential to the business, this exercise took time away from my current task of building the product. The business partners also had to wait for crucial insights from the data team, which delayed business decisions.
Since then, many efforts have been made to improve this workflow, saving the data team time and enabling the business partners to query the data easily without any latency.
Swiggy created Hermes [1], a text-to-SQL solution I wrote about in a LinkedIn Post. While they made the main functionality, concerns about data security remained. LinkedIn has talked about enforcing data governance and security while promoting data democratization.
If you don’t have as much time to review the whole article, here is a summary.
My key takeaways/opinions/summary
To build a successful text-to-SQL application powered by LLMs in your organization, the following significant points should be taken into consideration -
Rightful stress on certification and documentation of datasets, tables, and fields.
Giving as much context as possible in terms of table description and field descriptions - user and AI-generated.
User feedback and query logs are taken as domain knowledge and fed into the LLM context.
Multiple steps are taken (discovery, ranking) before and after (self-correction) the LLM writes the queries to increase the probability of a correct query.
It is equally essential to provide a user-friendly platform for the users to increase the adoption rate.
In the same sphere, the platform should enable the users to guide their query writing instead of just spewing out a generated query and calling it a day.
It is also necessary to create an application-specific benchmark to evaluate the performance of your LLM-powered system.
This is how LinkedIn developed their text-to-SQL solution -
Transforming natural language into SQL queries
LinkedIn recently developed its own text-to-SQL solution using LLMs called SQL Bot. This internal tool transforms natural language questions into SQL by finding the right tables, writing queries, and fixing errors.
Swiggy’s Hermes differs from LinkedIn’s SQL Bot in that LinkedIn implemented a multi-agent system using Langchain.
Strategies used to deploy a practical text-to-SQL solution -
Quality table metadata and personalized retrieval
Knowledge graph and LLMs for ranking, writing, self-correction
User experience with rich chat elements
Options for user customization
Quality table metadata and personalized retrieval
LinkedIn framed text-to-SQL as a retrieval augmented generation (RAG) application. This means that they used “embeddings” to retrieve the context semantically -
table schemas
example queries
domain knowledge
This also means that the tables should have descriptions of what they contain and should have descriptive names and fields along with descriptions of the fields.
Challenge #1
The description of tables and fields was missing. This meant LinkedIn couldn’t take advantage of the semantic retrieval using RAG.
Solution
They launched a company-wide data certification program. Domain experts identified key tables and added more context to them. Additionally, these descriptions were augmented by LLMs to increase retrieval accuracy further. They used Slack discussions and existing documentation to do so.
Challenge #2
What tables should the LLM consider when you have hundreds and thousands of tables?
Solution
The volume of tables can be narrowed down by looking at the frequently accessed tables.
Challenge #3
How should we discern what tables the user is talking about from the query - “What was the average CTR yesterday?”
Solution
The implicit context of the user’s query is solved by looking at the organization chart. The tables used are inferred from the user’s access history + the datasets usually accessed by those in that particular team. The user can decide to bypass these automatic inferred details by changing the default filters.
Challenge #4
What if some tables are deprecated or added over time?
Solution
LinkedIn has built a workflow using its in-house search and discovery tool - Datahub. Developers can mark popular datasets and fields as deprecated, which triggers a pipeline to ingest the new data automatically. This always keeps the embedding/vector store updated.
Agentic workflow for ranking, writing and self-correction

To generate queries, a deep semantic understanding of the available datasets is necessary. In addition to tables and fields, the following information is provided to the LLM to write queries -
table schemas, field description, top k values from specific categorical fields, partition keys, and classification of fields into metrics, dimensions and attributes
domain knowledge collected from users from the SQL bot’s UI
successful queries from logs to determine common joins, commonly used fields, and tables.
certified example queries from internal documentation

The agentic workflow comes into the picture after gathering all the above context -
A “sorting and filtering” agent is used only to narrow the scope of tables from the above context to 20 tables.
A “ranking” agent is used to rank the tables further and provides 7 tables for query writing. The ranking agent uses the table descriptions and other domain knowledge gathered in the context.
Another “ranking” agent is used to select fields from the selected tables using the field description context described above.
The SQL bot (agent) then generates a plan and solves each step of the plan incrementally to build the final query.
Finally, a “self-correction” agent looks at the EXPLAIN output of the SQL query to detect and correct syntax queries. This agent is equipped with tools to retrieve additional tables or fields if required.
Going the extra mile with user experience (SQL bot chat)
I was initially going to skip this section but realized how equally important it is to increase user adoption. What is the use of making a banger product if there are no users?
How did LinkedIn market this feature?
They integrated the SQL bot in their already widely used platform called DARWIN. A “Fix with AI” button allowed the developers to outsource fixing failed queries to the SQL bot.
Additionally, quick replies were provided near the text boxes, such as -
Update query
Update table selections
Explain these tables
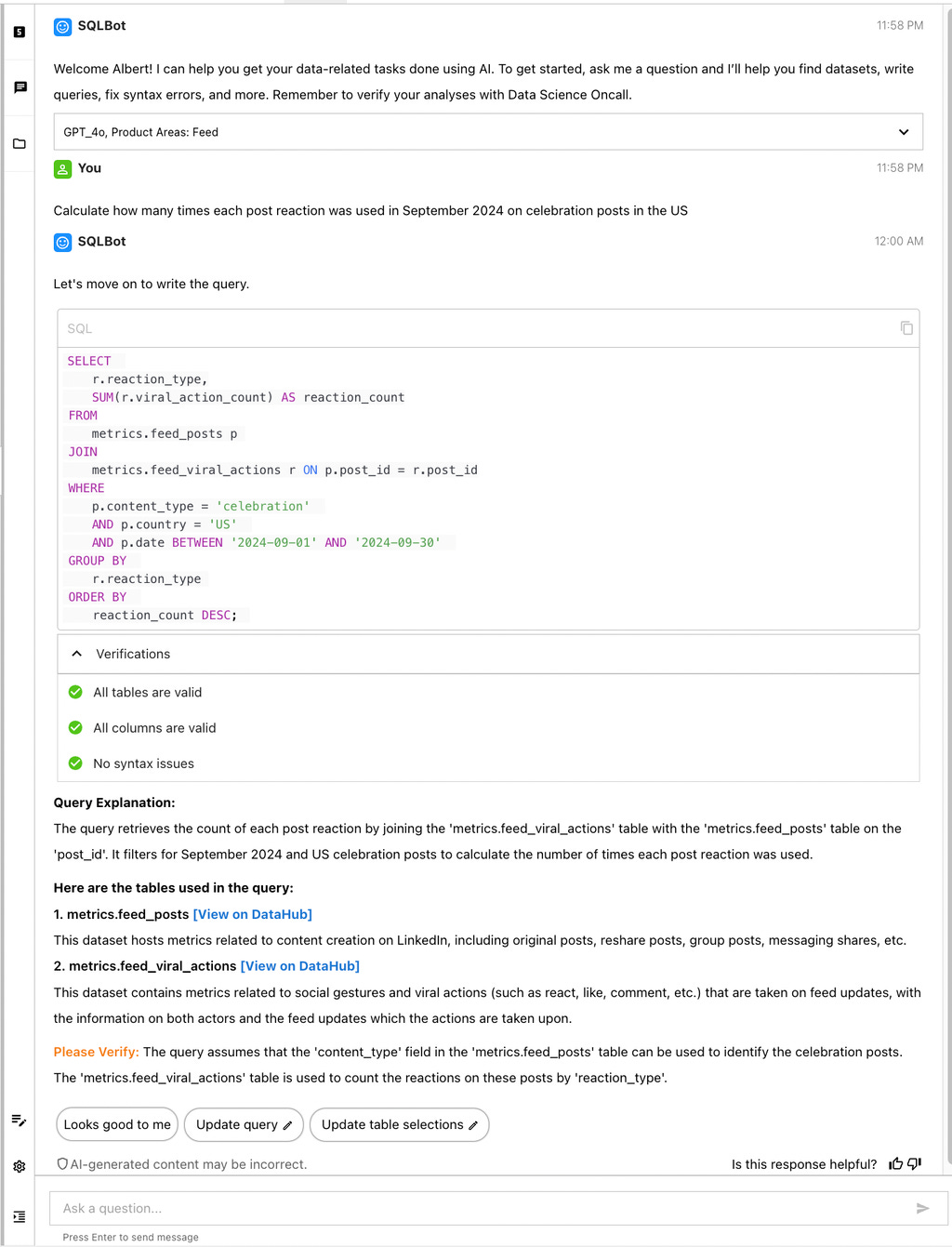
The chat functionality allowed developers to ask follow-ups and be informed about the fields and schema. This meant the developers had more control over the query-writing process instead of banking on the SQL bot to give a black-box query.
Options for user customization
LinkedIn allowed even more control in developers/users’ hands by allowing them to customize their experience in the following ways -
Dataset customization - Instead of getting restricted by the user’s organization chart to generate queries using a select number of tables used by the team, the users can now specify the users, datasets, and tables to be used by selecting the “product area” in the UI.
Custom instructions - If the system-designed prompts aren’t helpful, the users are also allowed to give custom instructions when writing queries.
Example queries - In the same sphere as custom instructions, if the user feels they are dealing with a not-before-seen query, they can provide some example queries, which will be fed into the vector store.
But how do we tell the SQL bot is performing well?
LinkedIn’s benchmarking
When you’re building an LLM-powered application, just like an ML model, there are certain hyper-parameters that you can tweak to increase the chosen evaluation metric. Some of the hyper-parameters can be -
Choice of text to embed/vectorize
Choice of context being passed to the LLM along with the query.
Representation of the above context and prompts
Management of agent memory
Number of times to run self-correction agent
Building a benchmark becomes difficult considering a variety of evaluations, including clarity of tables and column names, complexity of the desired queries, target response time, etc.
LinkedIn specifically focussed on the following evaluation metrics -
recall of tables and fields
table/field hallucination rate
syntax correctness
response latency
They measured the increase in table recall after adding re-rankers, descriptions, and example queries -

In addition to the initial evaluation metrics, they used human evaluation and LLMs-as-judge to evaluate the generated query accuracy further.
The above two - manual and semi-manual approaches - were used to score the following -
correctness regarding tables, columns, joins, filters, aggregations, etc.
quality of generated SQL query in terms of efficiency and complexity
This allowed them to avoid using the query outputs to determine the correctness of the generated query because it would require data access. Also, there were multiple ways (queries) of answering the same question.
So, an audit is performed every 3 months to add accepted answers to the benchmark. If there is a considerable disagreement between the LLMs-as-judge and human evaluations, that indicates there is a correct answer that is not currently in the benchmark.
References
Hermes by Swiggy - https://bytes.swiggy.com/hermes-a-text-to-sql-solution-at-swiggy-81573fb4fb6e
SQL bot by LinkedIn - https://www.linkedin.com/blog/engineering/ai/practical-text-to-sql-for-data-analytics