[ISSUE #13] Etsy's content moderation, Grab's efficient language translation service
Does Etsy care more about high precision or high recall during content moderation?

This week, we're all about improving user experience. Read on to learn more about how Grab and Etsy make it easy for users to use their platforms.
In this issue, we’ll be looking at -
🔍 How does Etsy moderate content for millions of users?
✍🏽 How has Grab improved their language translation service while being cost-efficient?
Machine Learning in Content Moderation at Etsy 🔍
Today, we're exploring an interesting case study from Etsy on how they leverage machine learning (ML) for content moderation. If you’re curious about how a platform with millions of unique, creative listings keeps things safe and compliant, it’s going to get interesting!
The Challenge: Curating a Safe Marketplace
Etsy is known for its community of independent sellers and unique products. However, with such diversity comes the challenge of ensuring that all content aligns with their policies and values. Whether it’s detecting prohibited items, managing spam, or handling sensitive materials, manual review alone wouldn’t cut it. The volume is simply too high.
Model Architecture
To overcome this obstacle, Etsy has concocted a multi-modal (text + image) architecture to identify violations of its policies.
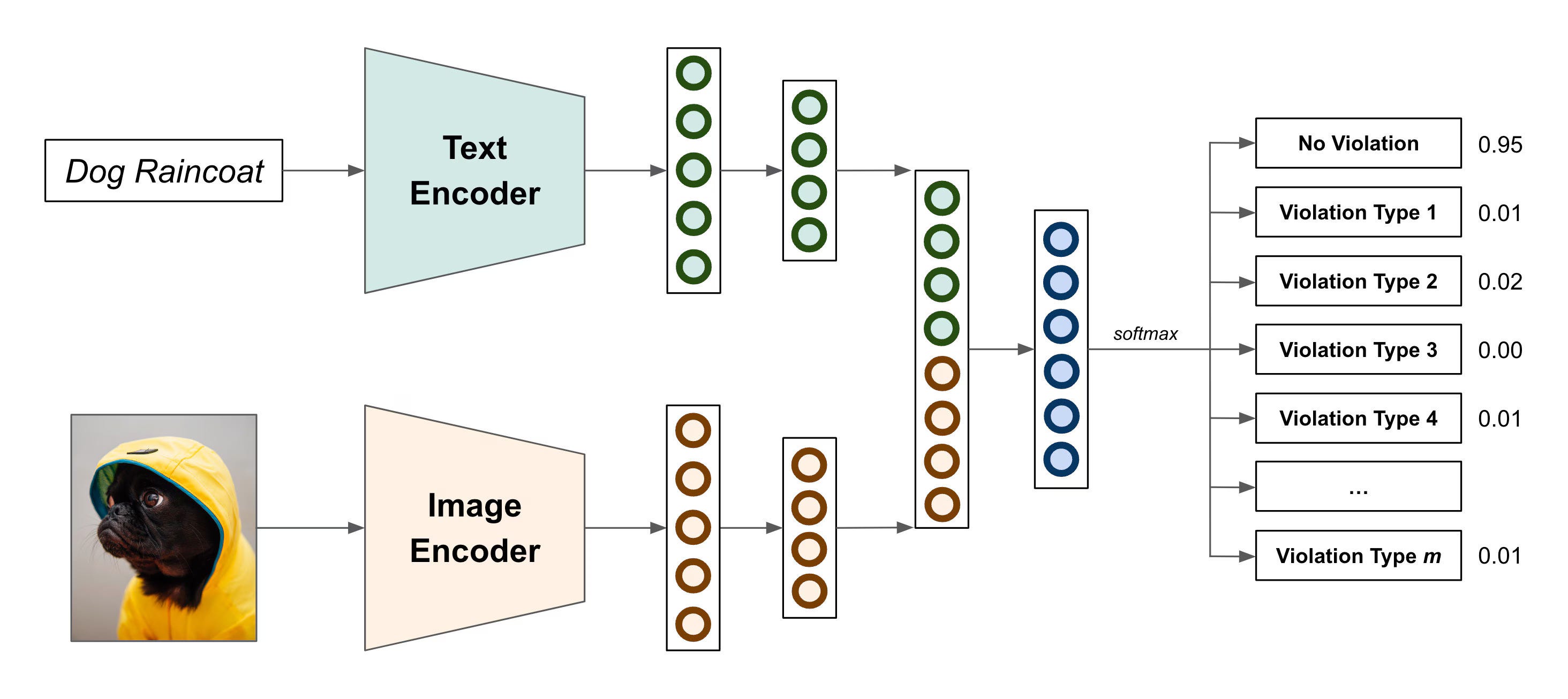
Text Encoder
Utilizing transformer models like BERT, this encoder processes text to capture the underlying meaning and context, helping the system flag any problematic language or policy violations with impressive accuracy. They also use ALBERT in cases where the situation warrants a faster inference because it works with 90% of the parameters of BERT.
Image Encoder
On the visual front, they have used a convolutional neural network, EfficientNet, to scrutinize product images. It’s adept at recognizing inappropriate or prohibited visual elements, ensuring that what’s displayed aligns with Etsy’s guidelines.
Bringing It All Together
The magic happens when these two encoders—text and image—come together. Etsy’s architecture combines the outputs from both encoders to form a comprehensive view of each listing. This integrated representation feeds into a final decision-making layer, a softmax activation layer.
Since this is a multi-label classification problem, the output layer comprises different violation types. One of those classes is essentially a “no violation” class, which accounts for most real-world cases. To address this imbalanced nature of the problem, a focal loss is used to penalize misclassified examples.
Results
A benchmark was established to evaluate the performance of this EmbraceNet-like model. The goal is to minimize the impact of wrong predictions on genuine sellers while successfully detecting any offending listings in the platform. This can be encapsulated in a precision-recall tradeoff.
A higher precision would guarantee that legitimate sellers are not wrongly accused of policy violations. However, the downside is that since the model is conservative, it might miss some problematic posts.
A higher recall ensures that the marketplace is safe for consumers. This means that the model is aggressive in tagging posts as problematic. This might cause some sellers to be annoyed because of wrongful tagging.
How Grab improved translation experience with cost efficiency ✍🏽
Grab is like Uber, offering rides, food delivery, and payment, among other things, predominantly in the Southeast Asian market. With the influx of tourists after COVID restrictions ended in 2023, the language barrier affected daily conversations between riders and users.
Translation necessity in Grab
Grab identified this problem and set out to solve it in an efficient but cost-effective way. They haven’t specified the exact models to train their detection and translation models. However, it is interesting to see the logistical problems they faced and how they overcame them. The three main objectives were -
Make translation available when required (detection)
Improve quality of translation (translation)
Maintain cost of translation service (scaling systems)
Existing solution overview
The user’s device language setting wasn’t enough to detect the language the user would communicate in. Hence, it became imperative to detect language on the fly. Initially, this was solved by a two-in-one third-party service that detected and translated the language.
Solving the language problem
The Grab team realized that there is a lack of open-source language detector models trained on Southeast Asian languages. As a compromise, they settled on Lingua, which supports 75 languages! However, it was a compromise because it still couldn’t detect the nuance between similar languages such as Malay and other Indonesian languages.
If the detection confidence falls beyond a certain threshold, the system falls back to the third-party translation service. The third-party service was costly and generic in nature.
Some assumptions were also made to help detect this: Booking/order happens in the same country, and drivers are always local to the country.
Low-cost translation service
Grab realized that their chat was highly specific to the rider and user conversation. That’s why they decided to make a lightweight in-house translation model. They followed the following steps -
Topic modeling: They used a stratified sampling approach to generate various unique groups of chat conversations, which not only represent the messages sent by their users but also capture all of the nuances in a general conversation.
Benchmark dataset creation: The reason to create their own benchmark dataset was two-fold -
to assess the translation quality of their in-house model
to build a high-quality set of translation examples for LLM conditioning/prompting to generate synthetic training data eventually
A benchmark score was obtained using the third-party translation service they originally used. They used the chrF++ score to evaluate this score. This became their baseline model to beat.
Synthetic data generation: A large-parameter open-source LLM was chosen for this purpose (they don’t specify which). They needed to make sure the tokenizer was appropriate to handle a diverse set of languages, especially ones with non-standard character set. The hand-curated benchmark dataset was used to prompt the model to generate 10 million high-quality synthetic training examples.
Model fine-tuning: Now, obviously, they could’ve used the same “prompted” large LLM as their translation model. But the logistics of deploying and inferring were infeasible. So, they fine-tuned another (unnamed) smaller model with the previously generated synthetic data. While being 99% smaller than the large LLM, it was 98% as effective.
Post-translation check: One problem they faced with this model was that it would change numbers (addresses, phone numbers). So, they added a programmatic check by counting the occurrences of each and then matching the same after translation. If it fails to match, they fall back on their third-party translation service.
Cost-effective and efficient methods
A number of techniques were applied to make it cost-effective. A caching layer was implemented, but it wasn’t effective. This is because the chats can be dynamic. They noticed that some of their standard and manual system messages were also getting translated with the same third-party service. They could save US$255K by just mandating that the system messages be manually translated since they don’t change much.
Interesting things around the world
I scroll through endless articles and Reddit and Twitter posts (so you don’t have to) and deliver the cream of the crop to you! If you would like a copy of this issue in your mailbox the next time I write, consider subscribing 🤗 Thanks for reading!
Welcome back :)
If you have the bandwidth, make your next one longer. Add some more explanations and 1-2 more case studies. I'll cross post it to AI Made Simple (my main publication) for my Wednesday reading list.