[ISSUE #12] ETA Reliability at Lyft, Text-to-SQL by Swiggy, Pinterest Text-to-Image Foundational Model
How does Lyft provide us with an accurate rider arrival estimate?

A little update - I’m experimenting by posting the short-form versions of the sub-articles that you see in this issue. I’ll be concising the individual articles on X as I come across them and compile them in this weekly issue at the end of the week.
In this issue, we’ll be looking at -
🚕 How does Lyft provide us with an accurate rider arrival time?
📜 A text-to-SQL solution developed by Swiggy: Hermes
👨🏼🎨 A creative way to market your products in Pinterest
Estimated Time of Arrival (ETA) Reliability at Lyft 🚕
Have you ever wondered how the cab sharing companies give us accurate ETAs on the ride before AND after we book one? From my experience, 9/10 times, the ETAs have been dependable. How does Lyft guarantee an accurate ETA? This article gives us a glimpse into Reliability.
Even before we hit the request button, there are algorithms which take into account the historical and real-time data, leveraging machine learning along with weather data, traffic, and marketplace fluctuations to give us that ETA.
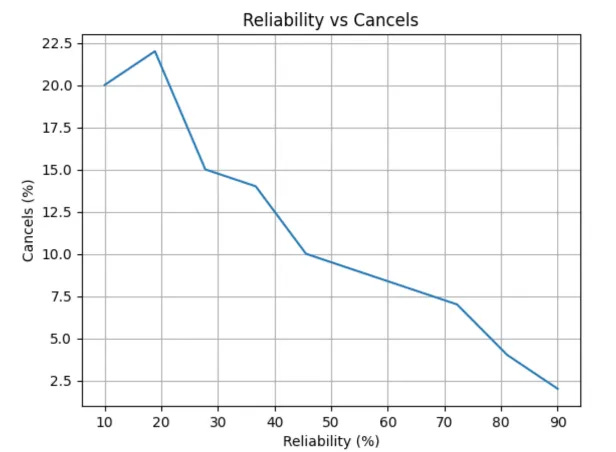
How does Lyft define reliability?
Before the ride is booked, reliability is the likelihood that the driver will arrive within a reasonable timeframe of the given ETA. After the ride is booked, reliability translates to how close to the given ETA does the driver actually arrive.
There are three major factors that affect estimated times of arrival -
Driver Unpredictability: Drivers have the autonomy to reject/cancel rides based on personal preference. They might receive multiple requests which affect the ETA for the riders who weren’t chosen. The drivers may also choose to log-off.
External Factors: Traffic is responsible for volatility in driver arrival times. Sometimes they might miss exits or take wrong turns. GPS inaccuracies might also contribute to longer arrival times.
Marketplace Dynamics: The supply and demand rideshare economics may also affect ETA. If a request comes from a high-demand neighborhood, there won’t be any drivers available in the immediate vicinity or they might be completing previous rides which makes it difficult to give an accurate ETA.
What model was used for ETA prediction?
The article outlines how causal inference could be used by leveraging historical data to predict ETA. They decided to harness the ML power to find complex relations between different features like driver availability, demand-supply economics, and ETA patterns. This ensured scalability and efficiency in their processes.
They used the Gradient-boosting tree-based classification model due to its clear interpretability, efficiency with smaller datasets, and robustness to outliers and missing values. They require less computation and are easy to implement and maintain. Deep learning approaches would have been an overkill for everyday lightweight classification tasks.
The features used to train the model were -
Driver-specific features: Estimated driving time, driver status (online, offline, completing trip), distance from the rider.
Historical statistics: Recent driver estimates and match times, number of completed and canceled rides.
Marketplace features: Realtime neighborhood-level demand and supply indicators such as app opens, unassigned rides and driver pool counts.
Miscellaneous features: Pick-up/drop-off locations, temporal elements.
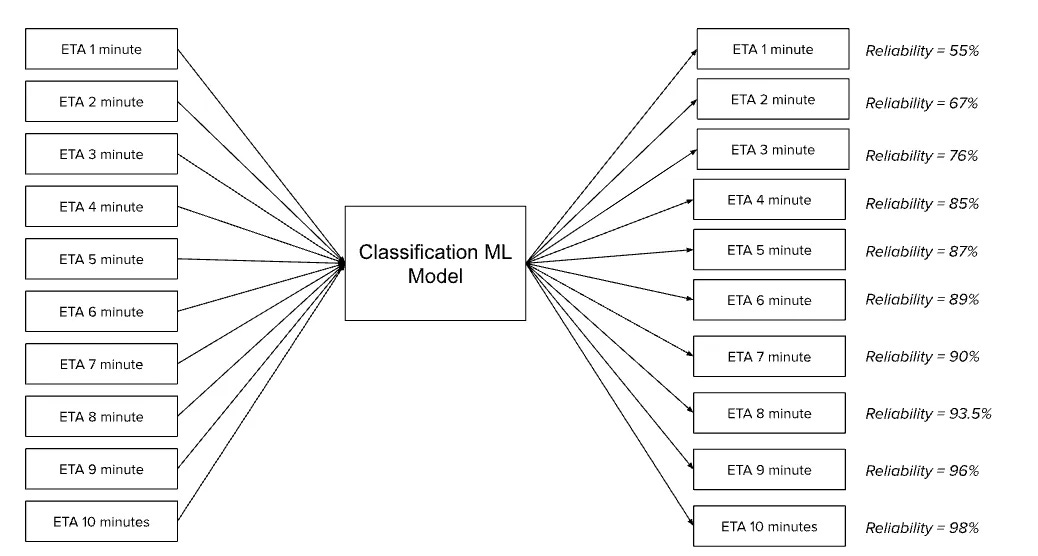
The model is trained on a multi-label classification task where the classes are discreet ranging from, let’s say, 1 to 10 mins (10 classes in this case). Each ETA will have a reliability score and the one with a score above a specified threshold (according to the downstream task) will be provided to the rider.
The model is evaluated using Area under the Curve (AUC) metric because it evaluates performance across all thresholds.
Model maintainability
It is difficult for Lyft to maintain its model accuracies with so many variables affecting the trained model. The data that the model is trained might become stale or inaccurate after some breaking changes in the app. Additionally, external factors affecting estimates might need to be added/modified in the model. Lyft has an advanced CI/CD system called LyftLearn composed of training, model serving, model monitoring, and feature serving which enables Lyft to establish alarms for accuracy dips and allows a faster retraining pipeline.
Hermes: A text-to-sql solution at Swiggy📜
Data allows us to make decisions backed by factual evidence. More often than not, retrieval of this data as information can be a long and arduous task involving couple of man hours and considerable time. This information is required by people at various levels - analysts, data scientists, product managers, and business teams. With the recent increase in reasoning and logic in large language models, one of the prime avenues for its application is natural language querying.
Want to know “how many times a section of law has been invoked in the past year by lawyer A in the Supreme court”? Immediately after reading that question, the following things came to my mind -
What tables do I need to query? What columns in those tables are of my concern?
What is the schema of the table that I’m working with for appropriate joins with other tables?
Do I already have existing queries which I have written in the past which I can re-use to get this question answered faster?
Swiggy rightfully incorporated the metadata answering all these questions in their bid to create a text-to-SQL model called Hermes V2. They considered a combination of tables, columns, reference queries, database schemas, and historical queries to be the most crucial pieces in the puzzle. Access to such a knowledge base (metadata) significantly improved their model accuracy and helped query disambiguation and contextual understanding.
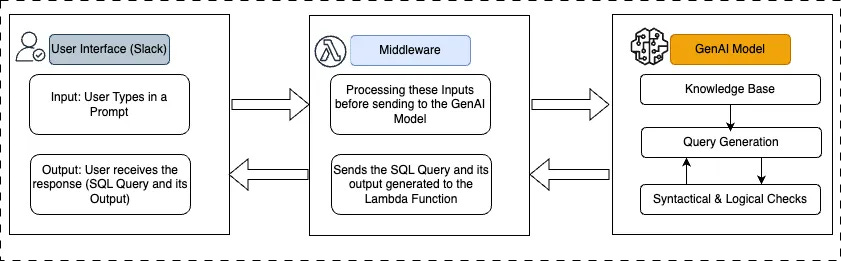
The Hermes V2 end-to-end pipeline looks like the following -
Metric Retrieval: Leverage the knowledge base to fetch the most relevant/historical queries via stored embedding vectors.
Table and column retrieval: Ensure the correct tables and columns are fetched by converting user queries into embeddings and searching the vectored knowledge base.
Structured prompt creation: All of the gathered information is compiled into one structured prompt which is then sent to the LLM for SQL generation.
Query validation: The generated SQL query is run against their databases to produce results. Upon errors, it is sent to an LLM for resolution with a fixed number of retries.
To keep the queries segregated based on various company functions, a separate charter is maintained which includes its own metadata. This helped Swiggy maintain accuracy in generated SQL. One of the future improvements that I’m excited about is the explanation of the generated query to make the user more confident in the consumption of the said query.
Building Pinterest Canvas, a text-to-image foundation model 👨🏼🎨
I’ve always felt that the Facebook marketplace listings have lackluster photos of the products showcased. Not taking away from the utility of the photos, but it makes looking at the listings a bit unappealing. This is true for Etsy, eBay, Pinterest, etc.
Recently, Pinterest recognized this gap in user experience and decided to build an in-house text-to-image foundational model. Now the immediate question that comes to mind is how would you be able to display “your” product if it’s generated by the AI. Pinterest trained a model named Canvas to accentuate the shown product with a product-appropriate background which bolsters the product even more. And the model is able to do this without interfering with the actual product.
That is where masking and conditioning images come into the picture (pun intended). The blog outlines the following
How Pinterest trained their foundational text-to-image model called Canvas?
How was this model fine-tuned to generate photo-realistic backgrounds conditioned on masks?
How can these generated images be stylized according to a given reference style (in an existing image)?
Foundational model
Pinterest has a dataset of 1.5 billion high-quality image-caption pairs. After the image is converted into a latent representation via a variational autoencoder (VAE), noise is added to this image latent. Parallely, the text caption is converted into embeddings using the popular CLIP model. This pairing of text and visual embeddings is then fed to a UNet model whose sole purpose is to regenerate the image. This trains a foundational text-to-image model called Canvas.
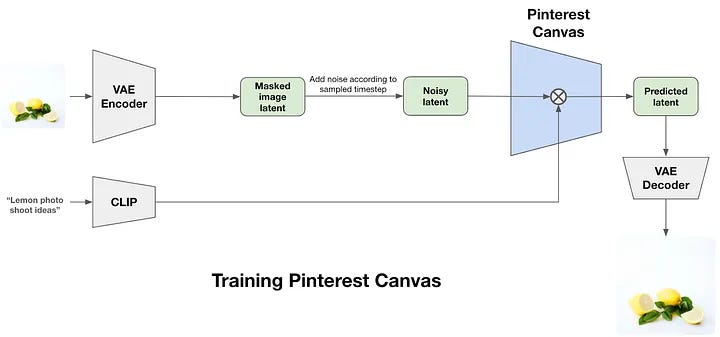
They also noted the use of reinforcement learning to generate more visually appealing and diverse images.
Fine-tuning
The training task is modified to fill in missing parts of an image. This is commonly referred to as out-painting. Instead of only passing a text caption and partially noisy latent, the following is passed -
An image with missing portions eg. a nail-polish remover with the background removed.
A binary mask of the above image; thus hinting the model at what is missing in the picture.
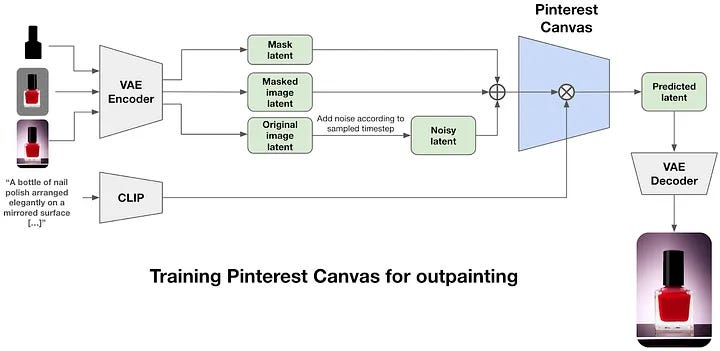
The end goal is to generate the target (whole) image again but with the missing portions filled in. The model is fine-tuned in two stages -
In the first stage, the same dataset is used while generating random masks for the model to in-paint. This stage teaches the model to fill in the missing regions in the image. One downside is that since the masks are not related to the product displayed in the image, the model adds extraneous details thus extending the original product in the image.
Hence, in the second stage, a semantic segmentation model is used to generate product-specific masks. Additionally, the original captions only describe the product itself. These captions are enhanced by using a visual LLM thus giving us more detailed and complete captions. This stage is trained using LoRA to enable rapid parameter-efficient fine-tuning. This stage is trained with highly-engaged promoted products on Pinterest to steer the model towards aesthetics.
Thus, the first stage gives the model the ability to in-paint while the second stage teaches the model to preserve product boundaries and focuses more on generating background content.
Personalizing Results
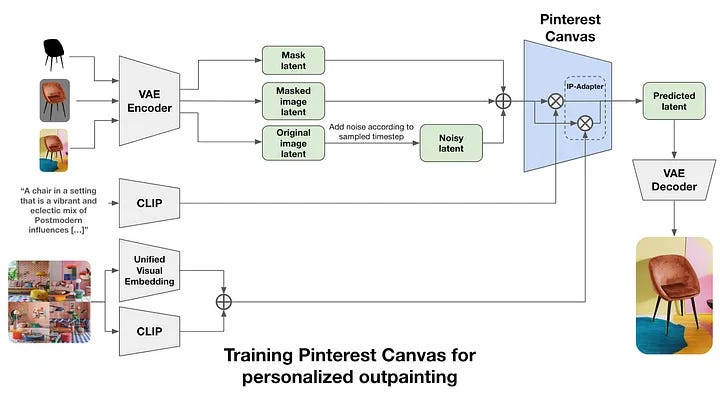
It’s easier to explain the style by just providing an image instead of explaining it in words. (A picture speaks a thousand words as they say). So what if we add an adapter to the fine-tuned model which will take a support style-image which will tell the model what kind of background image is expected. This is achieved by using the IP-Adapter method for training an adapter network that processes additional images. The additional image embeddings are sent along with the text embeddings to the new image-specific cross-attention layers.
Interesting things around the world 🌏
I scroll through endless articles and Reddit and Twitter posts (so you don’t have to) and deliver the cream of the crop to you! If you would like a copy of this issue in your mailbox the next time I write, consider subscribing 🤗 Thanks for reading!