

[ISSUE #11] Instagram Post Recommendation, Medical AI, Swiggy Delivery Time Prediction
How does Instagram know what reels I'll like?

Millions of videos posted every day, and somehow, my Instagram feed makes me exhale sharply through my nose very often. How is this made possible for billions of their users? In this issue, we’ll be looking at -
📸 How does Instagram personalize posts and scale it?
🩺 How can LLMs augment the use of specialized medical AI models?
🛵 How does Swiggy predict food delivery time?
How does Instagram personalize posts for you? 📸
At least 95 million photos and videos are posted on Instagram each day! Imagine how computationally heavy would it be to recommend something from that pool to all of 2 billion (and growing) monthly active users!
Due to real-world constraints and requirements, it makes sense to intelligently prune this pool of candidate posts based on user’s behavior on the app. There can be various “sources” (initial wells of content) from which the first thousand of recommendations can be sourced from -
heuristic sources (e.g. trending posts)
sources based on ML approaches (personalized page rank)
real-time capturing (most recent interactions)
pre-generated (capturing long-term interests)
All these different sources are weighted differently according to the person’s or group’s interests.
The user’s interactions with the posts (likes, shares and comments) and the posts themselves (image, video, caption) can be used as features to determine what posts should be recommended next. Keeping this in mind, Instagram uses the Two Tower Neural Network approach to retrieve relevant posts. Let’s take a brief look at how this approach works.
Two Tower NN
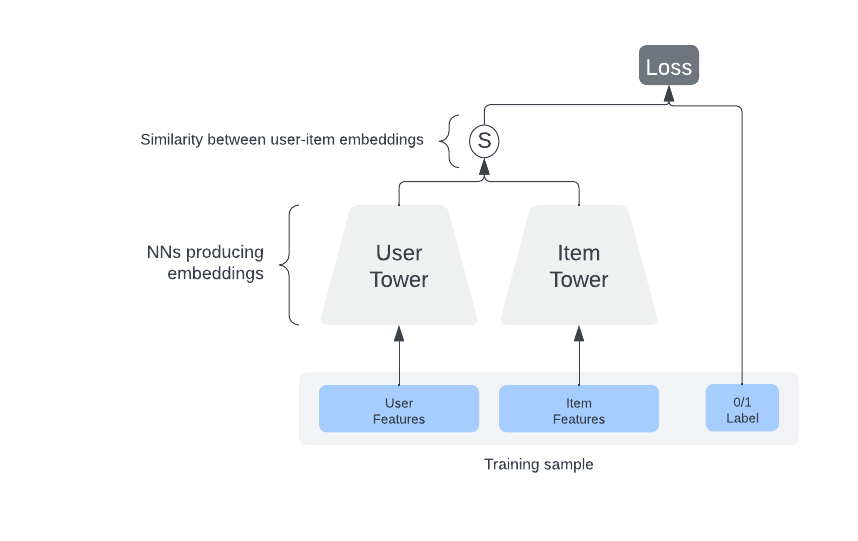
Two Tower model comprises two neural network models - one for the user and one for the item (post).
Each of the neural networks consumes features related to its own entity. (interactions for the user model; post metadata for the item model)
The learning objective is to measure the similarity between the user embedding and item embedding i.e., the closeness of the two embeddings should provide us with items that the user will most probably like or engage with (comment, share).
These embeddings can be used online (while the user is scrolling) and offline (during off-peak hours) fashion.
Using an offline pipeline, the item tower can be used to generate item embeddings, which can be used as candidates for recommendation. During online retrieval, the user tower can generate user embedding on the fly using user-side features.
Let’s say a user liked/saved/commented on some items. Given that we have the embeddings for these user interactions, we can find similar items from the historical repository of active items (most liked/shared) using an approximate nearest neighbor search (FAISS, HNSW, etc.).
Multimodal Medical AI 🩺
Medicine is a multimodal discipline. Medical professionals provide diagnoses based on complex inputs such as CT scans, X-rays, pathology slides, and genetic information. AI systems have been built using either of these complex inputs, providing a structured output. With the recent advancements in large language models, they have demonstrated the capability to interpret and respond in plain language. This article outlines the opportunities to bring new modalities to medical AI systems.
Using LLMs as an autonomous agent
LLMs can be used as a central agency to delegate and outsource data analysis to specialized subsystems. These sub-systems are independently optimized for specialized tasks. For example, the central LLM agency could forward a chest X-ray to a radiology AI and integrate that response. This radiology AI subsystem could be in the form of an API or multiple AI systems talking to each other for an even better outcome/response.
Since these communications happen over a human-readable channel, it enables auditability and debuggability. While interactivity between AI sub-systems allows for flexibility and additional vetting, getting this communication right can be tricky and may lead to miscommunication or information loss.
Grafting a specialized model on top of an LLM
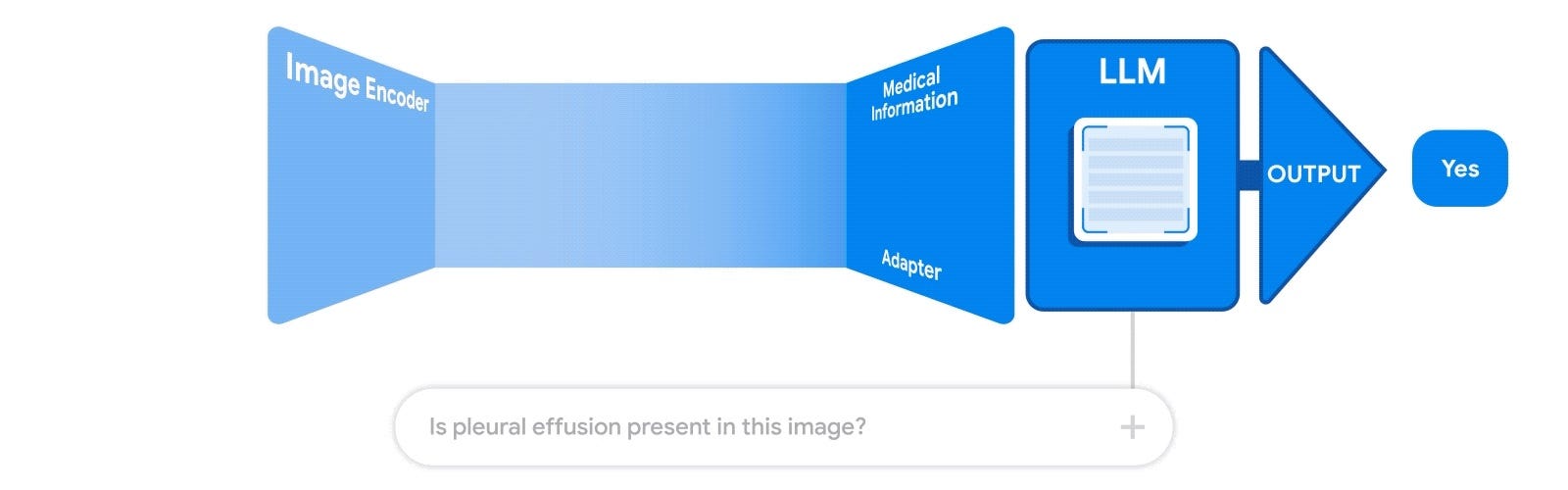
This method is concerned with adapting a specialized neural network model and plugging it directly into the LLM. There are a couple of ways grafting can take place.
In the paper, Multimodal LLMs for health grounded in individual-specific data, the neural network is trained to interpret spirograms, and then the output of the model is fed into the LLM for plain language reasoning.
Similarly, in this paper, which builds an X-ray artificial intelligence system, a similar stack is applied to a full-fledged image encoder model. The paper describes training a lightweight “adapter” that re-purposes the final layer of the encoder to output a series of tokens, which can then be used as LLM’s input embeddings. Thus, the resulting combination could be used for semantic search and visual question answering.
The advantage of using such a modular system of encoder-adapter-LLM is that the LLM is able to build on a highly optimized and validated model. Additionally, such a modular structure facilitates testing and debugging. However, one of the downsides is that this procedure warrants a new adapter every time the domain-specific encoder is revised.
Building a generalized model for all
Imagine a medical model able to absorb information from all the sources - images and text. The paper, Towards Generalist Biomedical AI, builds upon PaLM-E, a combination of an LLM (PaLM) and a vision encoder (ViT). LLM handles text and tabular data while images are fed to the vision encoder.
Once PaLM-E is fine-tuned on the medical domain data, it can make use of the multimodal biomedical information in a single interaction. It is then able to handle a diverse range of downstream tasks. With the same model weights handling all the tasks, it might not be the best candidate for specialized domains. Additionally, computational costs may suffer.
How does Swiggy predict food delivery time? 🛵
According to Swiggy, a food delivery service, the most crucial data point for a customer to follow through with an order is the promised delivery time. If it is too short, it may lead to the order being delayed, which in turn means an unhappy customer. If it is too conservative, the customer might rethink placing that order. Hence, Swiggy tries to operate within the Goldilocks zone.

Based on the performance of these estimates, customers tend to form a perception of the accuracy of these promises. That is why it is so important for Swiggy to accurately predict the delivery time. What are the most important factors affecting the delivery time?
Type of restaurant
Number of items in an order
Complexity of dishes in the order
Distance from restaurant to customer
Availability of delivery executive (demand)
How do we determine the accuracy of a model that predicts delivery time? Fundamentally, delivery time prediction is a regression problem, so mean absolute error (MAE) and mean squared error come to mind. Apart from these Swiggy measures its accuracy based on the following two metrics -
Bi-directional compliance - measures the percentage of target values +/- X of the predictions.
Egregious delay - measures the percentage of target values lying beyond a certain threshold of predictions.
Instead of predicting one numeric variable, they predict multiple target variables, which eventually add up to the delivery time. It includes the following -
Delivery time = time taken to assign a delivery executive + time taken to travel to the restaurant + wait time till order ready + time taken to travel to customer + time estimate to reach customer location
This type of granular estimates helps downstream use cases and hence requires a MIMO deep learning architecture.
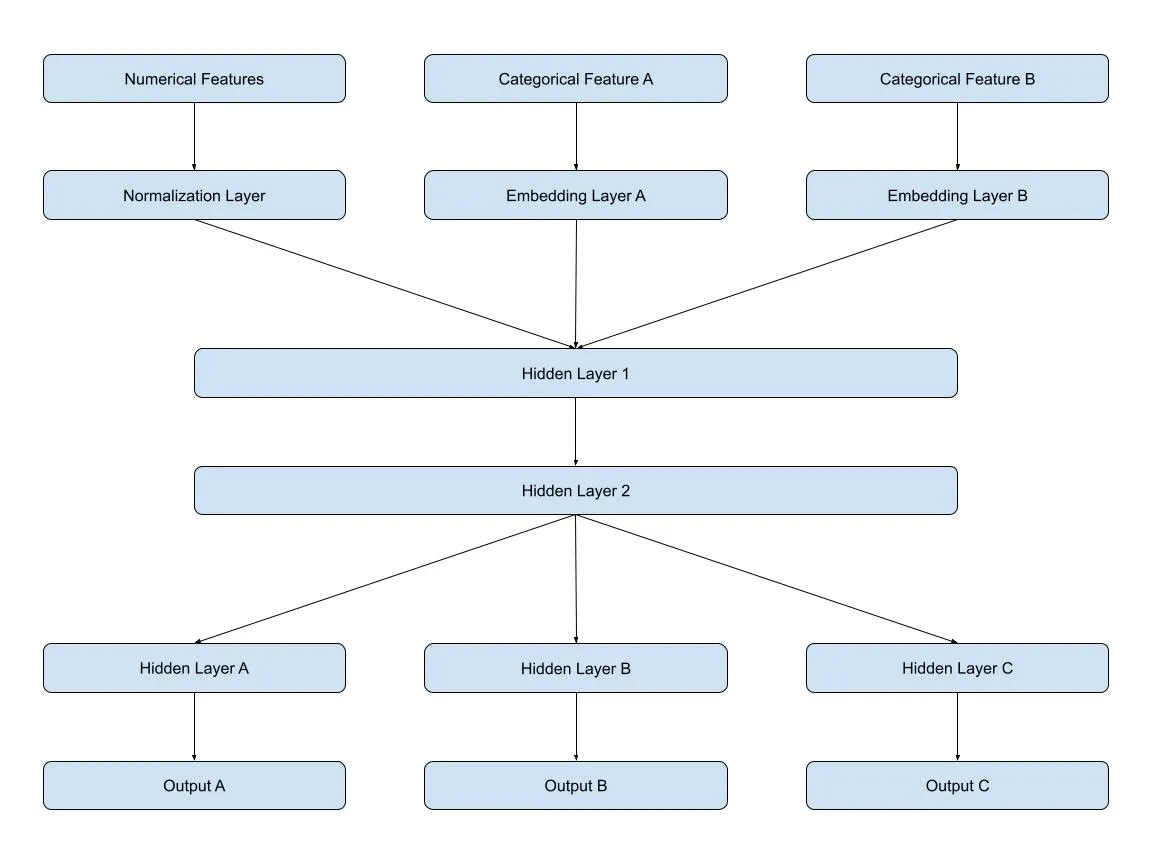
This architecture helps the target variables to share the same features, thus decreasing the training memory footprint. Furthermore, it was discovered that the combined network can learn relationships between the target variables. For example, the delivery executive assignment depends on the food preparation time of that restaurant, which also influences the travel time to the restaurant for the executive. The assignment and the travel time share the following features -
Supply and demand of delivery executives
Active orders
Historical assignment time and travel time to the restaurant as a function of the operation zone
Near real-time behavior of the restaurant
As a result of sharing features, Swiggy reduced its memory footprint by 50%. Additionally, the shared entity embeddings resulted in a 30% improvement in their evaluation metric (MAE) for order-to-assignment prediction.
Interesting things around the world 🌏
I scroll through endless articles and Reddit and Twitter posts (so you don’t have to) and deliver the cream of the crop to you! If you would like a copy of this issue in your mailbox the next time I write, consider subscribing 🤗 Thanks for reading!