[ISSUE #10] Netflix's Scene Change AI, Understanding GitHub Copilot, Etsy's Personalized Ads, eBay's Billion-Scale Vector Engine
What are the big ones cooking?

Writing this week’s issue made me realize that designing machine learning systems is a whole new paradigm. Deploying machine learning at scale focuses on reducing inference latency and making searching faster. It has given rise to vector database companies like Milvius and Pinecone to retrieve not data but high-dimensional intelligent representations.
In this issue -
📽️ How Netflix Uses AI to Detect Scene Changes and Memorable Moments
💻 GitHub Copilot: A Closer Look at How It Understands Your Code
💡 How Etsy Uses Deep Learning to Personalize Ads
⚡ eBay’s Blazingly Fast Billion-Scale Vector Similarity Engine
How Netflix Uses AI to Detect Scene Changes and Memorable Moments 📽️
Do you ever wonder how Netflix provides us with the most stand-out highlight of a particular show, thus making it intuitive to choose from a never-ending library of shows? They have built tools that help artists, and editors focus their time and energy on creativity rather than the labor-intensive task of watching the whole episode. These tools include video summarization, highlights detection, content-based video retrieval, dubbing quality assessment, and editing.
Most of these tools require a high-order understanding of the content within the show/episode. One pertains to detecting a scene change, that is, finding when a sequence of shots taken at the same place and time, and sharing the same characters and action, ends. Netflix uses two complementary approaches for scene boundary detection in audio-visual content -
Weak supervision: Screenplay text is leveraged to understand scene changes from the screenplay’s scene headers (sluglines). This is possible by aligning screenplay text with timed text (closed captions timestamps).
Supervised bi-directional LSTM models that use rich, pretrained shot-level embeddings.
Leveraging Aligned Screenplay Informat

If we can align the screenplay text with the closed caption timestamps in the video, we can leverage the headers in the screenplay to detect a scene change.
Screenplays are considered to be structured pieces of information with headers separating the scenes. They are even augmented with location and time of the day attributes, making them temporally rich. Unfortunately, this consistent formatting cannot always be banked upon because
Directors can change the scene on the fly, thus deviating from the screenplay.
Post-production and editing changes sometimes result in re-ordering, deleting, or completely inserting new scenes.
To address the first challenge, paraphrase identification determines the semantically similar lines in the scene versus the screenplay. This allows to sync the timestamps of the video over the screenplay, thus leveraging the sluglines to separate the various scenes in the movie/show.
To address the second challenge, a temporal (time + place) method called dynamic time warping (DTW) measures the similarity between two sequences. This algorithm makes the scenes speed and time agnostic, allowing for relative comparison.
A Multimodal Sequential Model (bidirectional GRU)

Most of the time, high-quality rich screenplays aren’t available, so there’s a need to train sequence models on annotated scene change data. Netflix already captures such data in their current workflows, and public datasets are also available.
The sequence model’s task is to determine whether the shot representation is the end of the scene. The inputs to the sequence model are -
Video embeddings - An in-house model pretrained on video clips paired with text is used to create these embeddings.
Audio embeddings - The creation of these embeddings is a multi-step process.
Audio source separation is performed to bifurcate foreground speech from background music/sound effects.
Each separate waveform is embedded using wav2vec2 and then concatenated to form the audio embeddings eventually.
Both of these embeddings are then fed to the biGRU model, which then outputs the probability of the shot being the end of the scene. Thus, Netflix uses a combination of text (screenplay), audio, and video to identify scene changes and memorable moments.
GitHub Copilot: A Closer Look at How It Understands Your Code 💻

Machine Learning (ML) researchers have done a lot of prompt engineering work so that the model provides contextually relevant responses with low latency. It provides developers with scaffolding to work on instead of starting from scratch.
But, like how?
It all comes down to prompts.
Copilot scans your current code snippet and comments and uses them to generate prompts automatically. These snippets and comments are assembled and prioritized into the final prompt.
Usually, while programming, a coder considers a wide array of contexts, including the pull requests, open issues, and other files in the repo, to say the least. Researchers at Github/OpenAI are improving Copilot’s contextual understanding to include the above “context” to generate customized suggestions.
The more accurate the prompt is, the more useful the predictions are for the user. To this effect, Copilot uses all the other files open in neighboring tabs in the IDE in addition to the current file you are working on. Copilot used to consider only the code before the cursor for the prompt. But soon, they introduced Fill in the Middle (FIM) paradigm that widened the context aperture by telling the model which part of the prompt is the prefix (before the cursor) or suffix (after the cursor).
Neighboring tabs contributed five more percent to developers accepting Copilot’s suggestions, while FIM added ten more. Optimal use of caching ensured neighboring tabs and FIM could work in the background without any added latency.
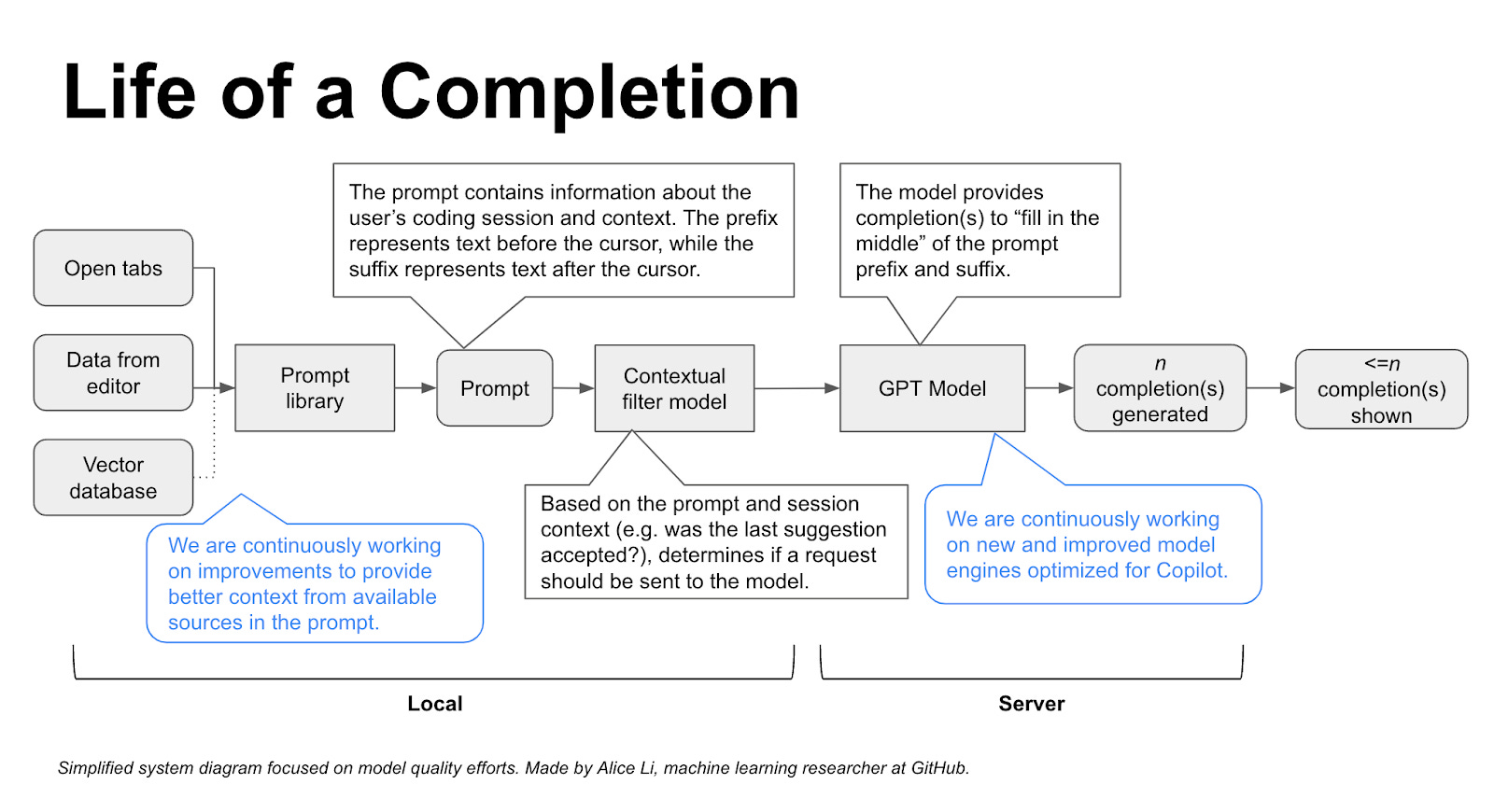
To summarize, this is how Copilot provides you with relevant code suggestions -
Embeddings of billions of code snippets are stored in a vector database.
While coding, your snippets (and context) are converted into embeddings.
Approximate nearest neighbor algorithms (FAISS, HNSW, ScaNN) retrieve the closest matching code snippets from the vector database.
The most asked question is - “Will this be/Is this useful?”. GitHub did a quantitative study and concluded that developers who used GitHub Copilot completed tasks 55% faster than those who didn’t. (sample size of developers = 95)
How Etsy Uses Deep Learning to Personalize Ads 💡
How do companies know what advertisement to serve you? Do they have a separate model for every one of their million users? How do they evaluate whether an ad is the best fit and would result in a conversion?
Etsy, a buyer-seller market for hand-made accessories, must ensure that a sponsored listing reaches the right audience. Such a targeted ad also ensures that the right product pops up on search based on user intent and results in a high conversion rate.
Etsy has introduced a new personalization method that uses a deep learning module to generate a dynamic user representation from a sequence of user actions. The new method called the adSformer Diversifiable Personalization Module (ADPM), is a three-component module that can learn from a variety of data sources, including user actions, item metadata, and visual features.

For example, if a user is browsing for lamps, the ADPM can consider their recent search queries, the items they have viewed, and the categories they have clicked on. The search content contains information about the visual and textual similarities in the listing. This information can generate a dynamic user representation that reflects the user's interests.
How do they achieve it? The ADPM module has three major components -
adSformer Encoder: This component learns a deep representation of the user’s action sequence.
Pretrained Representations: This component encodes rich images, text, and multimodal signals from all the items in the sequence. These are termed “rich” because each model has been trained offline using complex architectures (e.g., EfficientNetB0 for text on ImageNet data).
“On the Fly” Representation: These are lightweight representations for many different sequences for which pretrained representations aren’t available. For example, a sequence of favorited shops can be a feature and needs to be encoded in the model. This component is able to do so.

These three intermediary outputs are then fed to the ADPM model for a dynamic user representation. The ADPM is a general-purpose personalization module that can be used for various tasks, such as ad ranking and product recommendations. It is currently being used in Etsy Ads to improve the relevance of sponsored listings.
eBay’s Blazingly Fast Billion-Scale Vector Similarity Engine ⚡
The paradigm for building semantic matching systems is computing vector representations of the entities.
These vector representations are often called embeddings. Items that are close to each other in the embedding space are more similar to each other.

Why
Traditional nearest neighbor algorithms, like k-Nearest Neighbor Algorithm (kNN), are prohibitively computationally expensive and unsuitable for applications with a low latency response.
What
Approximate Nearest Neighbor (ANN) sacrifices perfect accuracy in exchange for executing efficiently in high dimensional embedding spaces at scale.
eBay uses HNSW and ScaNN (ANN algos)
Data structures like inverted files, trees, and neighborhood graphs are used under the hood.
Using these techniques, eBay can handle thousands of requests per second and returns similarity results in less than 25 milliseconds for 95 percent of the responses while searching through eBay's entire active inventory of 1.7 billion items.
The article goes deep into the following concepts, which feel out of context for this issue but are nonetheless interesting -
Data sharding, partitioning, and replication
ANN backend based on index building
Recall accuracy
Latencies
Memory footprint
The main reason to include this article in today’s newsletter is that I feel vector similarity search is really important today and gels well with the LLM use cases. AutoGPT, GPTEngineer, and other autonomous agents with external tool capabilities can’t function without this technology, and vector database companies are the ones to look out for! 💰
Interesting things around the world 🌏
Anthropic introduces Claude 2 with 100k tokens input context! (For reference, GPT4 has a 32k tokens input context)
Lost in the Middle paper analyzes LLMs with such huge input contexts, and they found out that LLMs are better at using info at the beginning and at the end of input context.
“gzip” utility beats transformers on text classifications!
I scroll through endless articles and Reddit and Twitter posts (so you don’t have to) and deliver the cream of the crop to you! If you would like a copy of this issue in your mailbox the next time I write, consider subscribing 🤗 Thanks for reading!